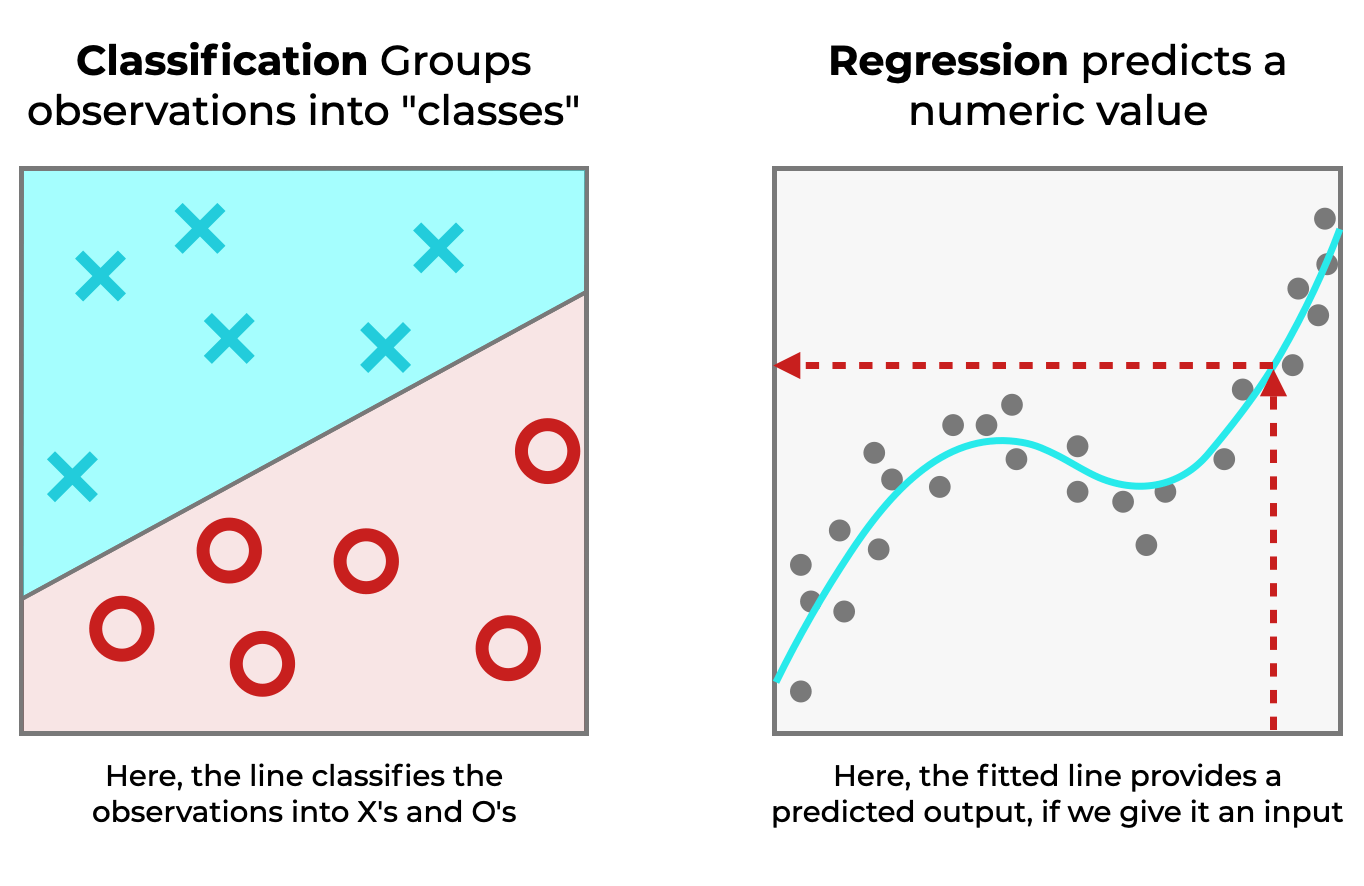
In the realm of data science and machine learning, two fundamental types of predictive modeling techniques exist: classification and regression. Each plays a critical role in analyzing data and making forecasts based on different types of target variables. While they may seem similar at first glance, understanding the difference between classification and regression is crucial for selecting the right approach for a given problem.
Classification is a technique used when the output variable is a category or class, such as "spam" or "not spam." This means that the model predicts discrete values, assigning data points to specific categories. On the other hand, regression is employed when the output variable is continuous, which could represent any numerical value, such as predicting house prices or temperature. Grasping these distinctions can significantly enhance the effectiveness of your predictive analytics.
Moreover, both classification and regression use various algorithms and techniques, but they differ in the metrics they use to evaluate their performance. For example, accuracy, precision, and recall are commonly used in classification tasks, while mean absolute error and R-squared are often employed in regression tasks. By understanding the difference between classification and regression, practitioners can tailor their methodologies to achieve better results and derive more meaningful insights from their data.
What is Classification?
Classification is a supervised learning technique where the model learns from labeled training data to classify new, unseen instances into predefined categories. This approach is widely used in various applications, such as:
- Email filtering (e.g., spam detection)
- Sentiment analysis (e.g., positive or negative reviews)
- Image recognition (e.g., identifying objects in photos)
- Medical diagnosis (e.g., classifying diseases based on symptoms)
How Does Classification Work?
To understand how classification works, consider the following steps:
- Data Collection: Gather a dataset containing labeled examples.
- Preprocessing: Clean and prepare the data for analysis.
- Model Training: Use algorithms like decision trees, random forests, or support vector machines to train the model.
- Model Evaluation: Assess the model's performance using metrics like accuracy, precision, and recall.
- Prediction: Deploy the model to classify new instances.
What is Regression?
Regression is another supervised learning technique, but unlike classification, it deals with continuous output variables. The goal of regression is to predict a numeric value based on input features. Common applications of regression include:
- Predicting stock prices
- Estimating sales revenue
- Forecasting weather conditions
- Analyzing customer lifetime value
How Does Regression Work?
Regression follows a similar process to classification, but with a few key differences:
- Data Collection: Gather a dataset with numerical output variables.
- Preprocessing: Clean and normalize the data to remove biases.
- Model Training: Use algorithms like linear regression, polynomial regression, or neural networks to create the model.
- Model Evaluation: Measure performance using metrics like mean absolute error (MAE) or R-squared.
- Prediction: Utilize the model to predict continuous values.
What are the Key Differences Between Classification and Regression?
The difference between classification and regression can be summarized through various aspects:
| Aspect | Classification | Regression |
|---|---|---|
| Output Type | Categorical | Continuous |
| Common Algorithms | Decision Trees, SVMs, KNN | Linear Regression, Neural Networks |
| Evaluation Metrics | Accuracy, Precision, Recall | MAE, R-squared |
| Use Cases | Email filtering, Image recognition | Price prediction, Weather forecasting |
When Should You Use Classification or Regression?
Choosing between classification and regression largely depends on the nature of the target variable:
- If the outcome is a category (e.g., “yes” or “no”), opt for classification.
- If the outcome is a numeric value (e.g., a price), select regression.
Can You Use Both Classification and Regression in One Problem?
Yes, it is possible to use both techniques in a single problem. This is often referred to as a hybrid model. For example, a business might use regression to predict sales revenue while simultaneously using classification to determine whether a customer will buy a product based on their demographic features.
Conclusion: Understanding the Difference Between Classification and Regression
In conclusion, the difference between classification and regression lies in the type of target variable and the methodologies employed to achieve predictions. By understanding their unique characteristics and applications, practitioners can make informed decisions about which approach to use for their data analysis tasks. Ultimately, mastering both techniques can significantly enhance the predictive power and overall effectiveness of data-driven models.
Article Recommendations
- Kill Fleas In House
- Madison Beer Nude Leak
- What Is A Mulligan
- Cast Of Hidden Figures
- Claudine Blanchard Crimes
- Clothes Not Smelling Fresh After Washing
- Outdoor Propane Heater Table Top
- How Did Jennifer Syme Pass Away
- Healthy Habits_0.xml
- Pioneer Dj